The difference here is that a man who has spent decades showing people the natural world has his voice being used in disingenuous ways, and it should give us all pause. I use generative artificial intelligence, as do many others, but there would be no way that I would even consider misrepresenting what I write or work on in the voice of someone else.
Who would do that? Why? It dilutes it. Sure, it can be funny to have a narration by someone like Sir David Attenborough, or Morgan Friedman, or… all manner of people… but to trot out their voices to misrepresent truth is a very grey area in an era of half-truths and outright lies being distributed on the Babel of the Internet.
Somewhere – I believe it was in Lessig’s ‘Free Culture’ – I had read that the UK allowed artists to control how their works were used. A quick search turned this up:
The Copyright, Designs and Patents Act 1988, is the current UK copyright law. It gives the creators of literary, dramatic, musical and artistic works the right to control the ways in which their material may be used. The rights cover: Broadcast and public performance, copying, adapting, issuing, renting and lending copies to the public. In many cases, the creator will also have the right to be identified as the author and to object to distortions of his work.
It would seem that something similar would have to be done with the voices and even appearance of people around the world – yet in an age moving toward artificial intelligence, where content has been scraped without permission, the only people who can actually stop doing this are the ones who are scraping the content.
The world of trusted humans is being diluted by untrustworthy humans.
This was a great question, and I want to flesh it out some more because Small Language Models (SLMs) are less processor and memory intensive than Large Language Models (LLMs).
Small isn’t always bad, large isn’t always good. My choice to go with a LLM instead of a SLM is pretty much as I responded to Stefan, but I wanted to respond more thoroughly.
I have a few use cases that I know of, one of which is writing – not having the LLM do the writing (what a terrible idea), but to help me figure things out as I’m going along. I’m in what some would call Discovery, or in the elder schools of software engineering, requirements gathering. The truth is that, like most humans, I’m stumbling along to find what I actually need help with.
For example, yesterday I was deciding on the name of a character. Names are important and can be symbolic, and I tend to dive down rabbit-holes of etymology. Trying to discern the meanings of names is an arduous process, made no better by the many websites that have baby names that aren’t always accurate or culturally inclusive. My own name has different meanings in India and in old Celtic, as an example, but if you search for the name you find more of a Western bias.
Before you know it, I have not picked a name but instead am perusing something on Wikipedia. It’s a time sink.
So I kicked it around with Teslai (I let the LLM I’m fiddling with pick it’s name for giggles). It was imperfect, and in some ways it was downright terrible, but it kept me on task and I came up with a name in less than 15 minutes in what could have easily eaten up a day of my time as I indulged my thirst for knowledge.
How often do I need to do that? Not very often, but so far, a LLM seems to be better at these tasks.
I’ve also been tossing it things I wrote for it to critique. It called me on not using an active voice on some things, and that’s a fair assessment – but it’s also gotten things wrong when reading some of what I wrote. As an example, when it initially read “Red Dots Of Life“, it got it completely wrong – it thought it was about how red dots were metaphors for what was important, when in fact, the red dots were about other people driving you to distraction to get what they thought was important.
Could a SLM do these things? Because they are relatively new and not trained on as many things, it’s unlikely but possible. The point is not the examples, but the way I’m exploring my own needs. In that regard – and this could be unfair to SLMs – I opted to go with more mature LLMs, at least right now, until I figure out what I need from a language model.
Maybe I will use SLMs in the future. Maybe I should be using one now. I don’t know. I’m fumbling through this because I have eclectic interests that cause eclectic needs. I don’t know what I will throw at it next, but being allegedly better trained has me rolling with LLMs for now.
So far, it seems to be working out.
In an odd way, I’m learning more about myself through the use of the language model as well. It’s not telling me anything special, but it provokes introspection. That has value. People spend so much time being told what they need by marketers that they don’t necessarily know what they could use the technology for – which is why Fabric motivated me to get into all of this.
Now, the funny thing is that the basis of LLMs and their owner’s needs to add more information into them is not something I agree with. I do believe that better algorithms are needed so that they can learn with less information. I’ve been correcting a LLM as a human who has not been trained on as much information as it has been, so there is a solid premise for tweaking algorithms rather than shoving more information in.
In that regard, we should be looking at SLMs more, and demanding more of them – but what do we actually need from them? The marketers will tell you what they want to sell you, and you can sing their song, or you can go explore on your own – as I am doing.
Can you do it with a SLM? Probably. I simply made the choice to use a LLM, and I believe it suits me – but that’s just an opinion, and I could be wrong and acknowledge it. Sometimes you just pick a direction and go and hope you’re going in the right general direction.
What’s right for you? I can’t tell you, that would be presumptuous. You need to explore your own needs and make as an informed decision as I have.
For Apple it’s a download, for Linux it’s simply copying and pasting a command line. Apple users who need help should skip to the section about loading models.
For Windows users, there’s a Windows version that’s a preview at the time of this writing. You can try that out if you want, or… you can just add Linux to your machine. It’s not going to break anything and it’s pretty quick.
“OMG Linux is Hard” – no, it isn’t.
For Windows 10 (version 2004 or higher), open a Windows Command Prompt or Powershell with administrator rights – you do this by right clicking the icon and selecting ‘with administrator rights’. Once it’s open, type:
WSL --install
Hit enter, obviously, and Windows will set up a distro of Linux for you on your machine that you can access in the future by just typing ‘WSL’ in the command prompt/PowerShell.
You will be prompted to enter a user name, as well as a password (twice to verify).
Remember the password, you’ll need it. It’s called a ‘sudo’ password, or just the password, but knowing ‘sudo’ will allow you to impress baristas everywhere.
Once it’s done, you can run it simply by entering “WSL” on a command prompt or powershell.
Congratulations! You’re a Linux user. You may now purchase stuffed penguins to decorate your office.
Installing Ollama on Linux or WSL.
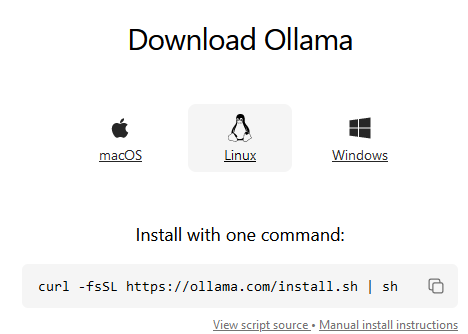
At the time of this writing, you’re one command away from running Ollama. A screenshot of it:
Hit the clipboard icon, paste it onto your command line, enter your password, and it will do it’s job. It may take a while, but it’s more communicative than a spinning circle: You can see how much it’s done.
Windows users: if your GPU is not recognized, you may have to search for the right drivers to get it to work. Do a search for your GPU and ‘WSL’, and you should find out how to work around it.
Running Ollama.
To start off, assuming you haven’t closed that window1, you can simply type:
You’re in. You can save versions of your model amongst other things, which is great if you’re doing your own fine tuning.
If you get stuck, simply type ‘/?‘ and follow the instructions.
Go forth and experiment with the models on your machine.
Just remember – it’s a model, it’s not a person, and it will make mistakes – correcting them is good, but doesn’t help unless you save your changes. It’s a good idea to save your versions with your names.
I’m presently experimenting with different models and deciding which I’ll connect to the Fabric system eventually, so that post will take longer.
If you did close the window on Windows, just open a new one with administrator privileges and type WSL – you’ll be in Linux again, and can continue. ↩︎
The last few days I’ve been doing some actual experimentation, initially begun because of Daniel Miessler’s Fabric, an Open Source Framework for using artificial intelligence to augment we lowly humans instead of the self-lauding tech bros whose business model falls to, “move fast and break things“.
It’s hard to trust people with that sort of business model when you understand your life is potentially one of those things, and you like that particular thing.
I have generative AIs on all of my machines at home now, which was not as difficult as people might think. I’m writing this part up because to impress upon someone how easy it was, I walked them through doing it in minutes over the phone on a Windows machine. I’ll write that up as my next post, since apparently it seems difficult to people.
For myself, the vision Daniel Miessler brought with his implementation, Fabric, is inspiring in it’s own way though I’m not convinced that AI can make anyone a better human. I think the idea of augmenting is good, and I think with all the infoglut I contend with leaning on a LLM makes sense in a world where everyone else is being sold on the idea of using one, and how to use it.
People who wax poetic about how an AI has changed their lives in good ways are simply waxy poets, as far as I can tell.
For me, with writing and other things I do, there can be value here and there – but I want control. I also don’t want to have to risk my own ideas and thoughts by uploading even a hint of them to someone else’s system. As a software engineer, I have seen loads of data given to companies by users, and I know what can be done with it, and I have seen how flexible ethics can be when it comes to share prices.
Why Installing Your Own LLM is a Good Idea. (Pros)
There are various reasons why, if you’re going to use a LLM, it’s a good idea to have it locally.
(1) Data Privacy and Security: If you’re an individual or a business, you should look after your data and security because nobody else really does, and some profit from your data and lack of security.
(2) Control and Customization: You can fine tune your LLM on your own data (without compromising your privacy and security). As an example, I can feed a LLM various things I’ve written and have it summarize where ideas I’ve written about connect – and even tell me if I have something published where my opinion has changed- without worrying about handing all of that information to someone else. I can tailor it myself – and that isn’t as hard as you think.
(3) Independence from subscription fees; lowered costs: The large companies will sell you as much as you can buy, and before you know it you’re stuck with subscriptions you don’t use. Also, since the technology market is full of companies that get bought out and license agreements changed, you avoid vendor lock-in.
(4) Operating offline; possible improved performance: With the LLM I’m working on, being unable to access the internet during an outage does not stop me from using it. What’s more, my prompts aren’t queued, or prioritized behind someone that pays more.
(5) Quick changes are quick changes: You can iterate faster, try something with your model, and if it doesn’t work, you can find out immediately. This is convenience, and cost-cutting.
(6) Integrate with other tools and systems: You can integrate your LLM with other stuff – as I intend to with Fabric.
(7) You’re not tied to one model. You can use different models with the same installation – and yes, there are lots of models.
The Cons of Using a LLM Locally.
(1) You don’t get to hear someone that sounds like Scarlett Johansson tell you about the picture you uploaded1.
(2) You’re responsible for the processing, memory and storage requirements of your LLM. This is surprisingly not as bad as you would think, but remember – backup, backup, backup.
(3) If you plan to deploy a LLM as a business model, it can get very complicated very quickly. In fact, I don’t know all the details, but that’s nowhere in my long term plans.
Deciding.
In my next post, I’ll write up how to easily install a LLM. I have one on my M1 Mac Mini, my Linux desktop and my Windows laptop. It’s amazingly easy, but going in it can seem very complicated.
What I would suggest about deciding is simply trying it, see how it works for you, or simply know that it’s possible and it will only get easier.
Oh, that quote by Diogenes at the top? No one seems to have a source. Nice thought, though a possible human hallucination.
OK, that was a cheap shot, but I had to get it out of my system. ↩︎
While different in some ways, voice actors Paul Skye Lehrman and Linnea Sage are suing Lovo for similar reasons. They got hired to do some work that they thought were one off voice overs, then heard their voices saying things they had never said. To the point, they heard their voices doing something that they didn’t get paid for.
The way they found out was oddly poetic.
Last summer, as they drove to a doctor’s appointment near their home in Manhattan, Paul Skye Lehrman and Linnea Sage listened to a podcast about the rise of artificial intelligence and the threat it posed to the livelihoods of writers, actors and other entertainment professionals.
The topic was particularly important to the young married couple. They made their living as voice actors, and A.I. technologies were beginning to generate voices that sounded like the real thing.
But the podcast had an unexpected twist. To underline the threat from A.I., the host conducted a lengthy interview with a talking chatbot named Poe. It sounded just like Mr. Lehrman.
“He was interviewing my voice about the dangers of A.I. and the harms it might have on the entertainment industry,” Mr. Lehrman said. “We pulled the car over and sat there in absolute disbelief, trying to figure out what just happened and what we should do.”
They aren’t sex symbols like Scarlett Johansson. They weren’t the highest paid actresses in 2018 and 2019. They aren’t seen in major films. Their problem is just as real, just as audible, but not quite as visible. Forbes covered the problems voice actors faced in October of 2023.
…Clark, who has voiced more than 100 video game characters and dozens of commercials, said she interpreted the video as a joke, but was concerned her client might see it and think she had participated in it — which could be a violation of her contract, she said.
“Not only can this get us into a lot of trouble if people think we said [these things], but it’s also, frankly, very violating to hear yourself speak when it isn’t really you,” she wrote in an email to ElevenLabs that was reviewed by Forbes. She asked the startup to take down the uploaded audio clip and prevent future cloning of her voice, but the company said it hadn’t determined that the clip was made with its technology. It said it would only take immediate action if the clip was “hate speech or defamatory,” and stated it wasn’t responsible for any violation of copyright. The company never followed up or took any action.
“It sucks that we have no personal ownership of our voices. All we can do is kind of wag our finger at the situation,” Clark told Forbes…
As you can see – the whole issue is not new. It just became more famous because of a more famous face, and involves OpenAI, a company that has more questions about their training data than ChatGPT can answer, so the story has sung from rooftops.
Sony recently warned AI companies about unauthorized use of the content they own, but when one’s content is necessarily public, how do you do that?
How much of what you post, from writing to pictures to voices in podcasts and family videos, can you control? It costs nothing, but it costs futures of individuals. And when it comes to training models, these AI companies are eroding the very trust they need from those that they want to sell their product to – unless they’re just enabling talentless and incapable hacks to take over jobs that talented and capable people have already do.
We have more questions than answers, and the trust erodes as more and more people are impacted.
India is the world’s most populous democracy, and there has been a lot going on related to religion that is well beyond the scope of this, but deserves mention because violence has been involved.
This, apparently, was a test, according to TheGuardian.
How this happened seems a little strange and is noteworthy1:
“…The adverts were created and submitted to Meta’s ad library – the database of all adverts on Facebook and Instagram – by India Civil Watch International (ICWI) and Ekō, a corporate accountability organisation, to test Meta’s mechanisms for detecting and blocking political content that could prove inflammatory or harmful during India’s six-week election…”
It’s hard to judge the veracity of the claim based on what I dug up (see the footnote). TheGuardian must have more from their sources for them to be willing to publish the piece – I have not seen this before with them – so I’ll assume good and see how this pans out.
“…Across the ideological spectrum, they’re relying on AI to help them navigate the nation’s 22 official languages and thousands of regional dialects, and to deliver personalized messages in farther-flung communities. While the US recently made it illegal to use AI-generated voices for unsolicited calls, in India sanctioned deepfakes have become a $60 million business opportunity. More than 50 million AI-generated voice clone calls were made in the two months leading up to the start of the elections in April—and millions more will be made during voting, one of the country’s largest business messaging operators told WIRED.
Jadoun is the poster boy of this burgeoning industry. His firm, Polymath Synthetic Media Solutions, is one of many deepfake service providers from across India that have emerged to cater to the political class. This election season, Jadoun has delivered five AI campaigns so far, for which his company has been paid a total of $55,000. (He charges significantly less than the big political consultants—125,000 rupees [$1,500] to make a digital avatar, and 60,000 rupees [$720] for an audio clone.) He’s made deepfakes for Prem Singh Tamang, the chief minister of the Himalayan state of Sikkim, and resurrected Y. S. Rajasekhara Reddy, an iconic politician who died in a helicopter crash in 2009, to endorse his son Y. S. Jagan Mohan Reddy, currently chief minister of the state of Andhra Pradesh. Jadoun has also created AI-generated propaganda songs for several politicians, including Tamang, a local candidate for parliament, and the chief minister of the western state of Maharashtra. “He is our pride,” ran one song in Hindi about a local politician in Ajmer, with male and female voices set to a peppy tune. “He’s always been impartial.”…”
In the broader way it is being used, audio deepfakes have people really believing that they were called personally by candidates. This has taken robo-calling to a whole new level3.
What we are seeing is the manipulation of opinions in a democracy through AI, and it’s something that while happening in India now is certainly worth being worried about in other nations. Banning something in one country, or making it illegal, does not mean that foreign actors won’t do it where the laws have no hold.
Given India’s increasing visible stance in the world, we should be concerned, but given AI’s increasing visibility in global politics to shape opinions, we should be very worried indeed. This is just what we see. What we don’t see is the data collected from a lot of services, and how they can be used to decide who is most vulnerable to particular types of manipulation, and what that means.
We’ve built a shotgun from instructions on the Internet and have now loaded it and pointed it at the feet of our democracies.
That’s pretty strange. The preceding report referenced in the article is here on LondonStory.org. Neither the ICWI or Eko websites seem to have that either. Having worked with some NGOs in the Caribbean and Latin America, I know that they are sometimes slow to update websites, so we’ll stick a pin in it. ↩︎
Likely paywalled if you’re not a Wired.com subscriber, and no quotes would do it justice. Links to references provided. ↩︎
I worked for a company that was built on robocalling, but went to higher ground with telephony by doing emergency communications instead, so it is not hard for me to imagine how AI can be integrated into it. ↩︎
Last week, there were a lot of announcements, but really not that much happened. And for some strange reason, Google didn’t think to use the .io ccTLD for their big annual developer event, Google I/O.
It was so full of AI that they should have called it Google AI. I looked over the announcements, the advertorials on websites announcing stuff that could almost be cool except… well, it didn’t seem that cool. In fact, the web search on Google with AI crutches already has workarounds to bypass the AI – but I have yet to see it in Trinidad and Tobago. Maybe it’s not been fully rolled out, or maybe I don’t use Google as a search engine enough for me to spot it.
No one I saw in the Fediverse was drooling over anything that Google had at the conference. Most comments were about companies slapping AI on anything and making announcements, which it does seem like.
I suppose, too, that we’re all a little bit tired of AI announcements that really don’t say that much. OpenAI, Google, everyone is trying to get mindshare to build inertia, but questions on what they’re feeding learning models, issues with ethics and law… and for most people, knowing that they’ll have a job they can depend on better than they can depend on it today seems more of a pressing issue.
The companies selling generative AI like snake oil to cure all the ills of the world seem disconnected from the ills of the world, and I’ll remember Sundar Pichai said we’d need more lawyers a year ago.
It’s not that generative AI is bad. It’s that it’s really not brought anything good for most people except a new subscription, less job security, and an increase in AI content showing up all over, bogging down even Amazon.com’s book publishing.
They want us to buy more of what they’re selling even as they take what some are selling to train their models to… sell back to us.
Really, all I ever wanted from Google was a good search engine. That sentiment seems to echo across the Fediverse. As it is, they’re not as good a search engine as they used to be – I use Google occasionally. Almost as an accident.
I waited a week for something to write about some of the announcements, and all I read about Google’s stuff was how to work around their search results. That’s telling. They want more subscribers, we want more income to afford the subscriptions. Go figure.
Wikipedia, a wonderful resource despite all the drama that comes with the accumulation of content, is having some trouble dealing with the the large language model (LLMs) AIs out there. There are two core problems – the input, and the output.
“…The current draft policy notes that anyone unfamiliar with the risks of large language models should avoid using them to create Wikipedia content, because it can open the Wikimedia Foundation up to libel suits and copyright violations—both of which the nonprofit gets protections from but the Wikipedia volunteers do not. These large language models also contain implicit biases, which often result in content skewed against marginalized and underrepresented groups of people.
The community is also divided on whether large language models should be allowed to train on Wikipedia content. While open access is a cornerstone of Wikipedia’s design principles, some worry the unrestricted scraping of internet data allows AI companies like OpenAI to exploit the open web to create closed commercial datasets for their models. This is especially a problem if the Wikipedia content itself is AI-generated, creating a feedback loop of potentially biased information, if left unchecked…”
Inheriting the legal troubles of companies that built AI models by taking shortcuts seems like a pretty stupid thing to do, but there are companies and individuals doing it. Fortunately, the Wikimedia Foundation is a bit more responsible, and is more sensitive to biases.
Using a LLM to generate content for Wikipedia is simply a bad idea. There are some tools out there (I wrote about Perplexity.ai recently) that do the legwork for citations, but with Wikipedia, not all citations are necessarily on the Internet. Some are in books, those dusty tomes where we have passed down knowledge over the centuries, and so it takes humans to be able to not just find those citations, but assess them and assure that other citations of other perspectives are involved1.
As they mention in the article, first drafts are not a bad idea, but they’re also not a great idea. If you’re not vested enough in a topic to do the actual reading, should you really be editing a community encyclopedia? I don’t think so. Research is an important part of any accumulation of knowledge, and LLMs aren’t even good shortcuts, probably because the companies behind them took shortcuts.
The Output of Wikipedia.
I’m a little shocked that Wikipedia might not have been scraped by the companies that own LLMs, considering just how much they scraped and from whom. Wikipedia, to me, would have been one of the first things to scrape to build the learning model, as would have been Project Gutenberg. Now that they’ve had the leash yanked, maybe they’re asking for permission now, but it seems peculiar that they would not have scraped that content in the first place.
Yet, unlike companies that simply cash in on the work of volunteers, like Huffington Post, StackOverflow, and so on, Wikimedia has a higher calling – and cashing in on volunteer works would likely cause less volunteers. Any sort of volunteer does so for their own reasons, but in an organization they collectively work toward something. The Creative Commons Licensing Wikipedia has requires attribution, and LLMs don’t attribute anything. I can’t even get ChatGPT to tell me how many books it’s ‘read’.
What makes this simple is that if all the volunteer work from Wikipedia is shoved into the intake manifold of a LLM, and that LLM is subscription based, and volunteers would have to pay to use it, it’s a non-starter.
We All Like The Idea of an AI.
Generally speaking, the idea of an AI being useful for so many things is seductive, from Star Trek to Star Wars. I wouldn’t mind an Astromech droid, but where science fiction meets reality, we are stuck with the informational economy and infrastructure we have inherited over the centuries. Certainly, it needs to be adapted, but there are practical things that need to be considered outside of the bubbles that a few billionaires seem to live in.
Taking the works of volunteers and works from the public domain2 to turn around and sell them sounds Disney in nature, yet Mickey Mouse’s fingerprints on the Copyright Act have helped push back legally on the claims of copyright. Somewhere, there is a very confused mouse.
Honestly, I’d love a job like that, buried in books. ↩︎
Disney started off by taking public domain works and copyrighting their renditions of them, which was fine, but then they made sure no one else could do it – thus the ‘fingerprints’. ↩︎
The recent news of Stack Overflow selling it’s content to OpenAI was something I expected. It was a matter of time. Users of Stack Overflow were surprised, which I am surprised by, and upset, which I’m not surprised by.
That seems to me a reasonable response. Who wouldn’t? Yet when we contribute to websites for free on the Internet and it’s not our website, it’s always a terrible bargain. You give of yourself for whatever reason – fame, prestige, or just sincerely enjoying helping, and it gets traded into cash by someone else.
But companies don’t want you to get wise. They want you to give them your content for free so that they can tie a bow around it and sell it. You might get a nice “Thank you!” email, or little awards of no value.
No Good Code Goes Unpunished.
The fallout has been disappointing. People have tried logging in and sabotaging their top answers. I spoke to one guy on Mastodon a few days ago and he got banned. It seems pretty obvious to me that they had already backed up the database where all the stuff was, and that they would be keeping an eye on stuff. Software developers should know that. There was also some confusion about the Creative Commons licensing the site uses versus the rights given to the owners of the website, which are mutually exclusive.
Is it slimy? You bet. It’s not new, and the companies training generative AI have been pretty slimy. The problem isn’t generative AI, it’s the way the companies decide to do business by eroding trust with the very market for their product while poisoning wells that they can no longer drink from. If you’re contributing answers for free that will be used to train AI to give the same answers for a subscription, you’re a silly person1.
These days, generative AI companies need to put filters on the front of their learning models to keep small children from getting sucked in.
Remember Huffington Post?
Huffington Post had this neat little algorithm for swapping around headlines til it found one that people liked, it gamed SEO, and it built itself into a powerhouse that almost no one remembers now. It was social, it was quirky, and it was fun. Volunteers put up lots of great content.
I knew a professional journalist who was building up her portfolio and added some real value – I met her at a conference in Chicago probably a few months before the sale, and I asked her why she was contributing to HuffPost for free. She said it was a good outlet to get some things out – and she was right. When it sold, she was angry. She felt betrayed, and rightfully so I think.
It seems people weren’t paying attention to that. I did2.
You live, you learn, and you don’t do it again. With firsthand and second hand experience, if I write on a website and I don’t get paid, it’s my website. Don’t trust anyone who says, “Contribute and good things will happen!”. Yeah, they might, but it’s unlikely it will happen for you.
If your content is good enough for a popular site, it’s good enough to get paid to be there. You in the LinkedIn section – pay attention.
The question we should be asking is whether it’s worth putting anything on the Internet at this point, just to have it folded into a statistical algorithm that chews up our work and spits out something like it. Sure, there are copyright lawsuits happening. The argument of transformative works doesn’t really work that well in a sane mind when it comes to the exponentially higher amount of content used to create a generative AI at this point.
So what happens when less people contribute their own work? One thing is certain: the social aspect of the Internet will not thrive as well.
Social.
The Stack Overflow website was mainly an annoyance for me over the years, but I understand that many people had a thriving society of a sort there. It was largely a meritocracy, as open source, at least at it’s core. You’ll note that I’m writing of it in the past tense – I don’t think anyone with any bit of self-worth will contribute there anymore.
The annoyance aspect for me came from (1) Not finding solutions to the quirky problems that people hired me to solve3, and (2) Finding code fragments I tracked down to Stack Overflow poorly (if at all) adapted to the employer or client needs. I also had learned not to give away valuable things for free, so I didn’t get involved. Most, if not all, of the work I did required my silence on how things worked, and if you get on a site like StackOverflow – your keyboard might just get you in trouble. Yet the problem wasn’t the site itself, but those who borrowed code like it was a cup of sugar instead of a recipe.
Beyond we software engineers, developers, whatever they call themselves these days, there are a lot of websites with social interaction that are likely getting their content shoved into an AI learning model at some point. LinkedIn, owned by Microsoft, annoyingly in the top search results, is ripe for being used that way.
LinkedIn doesn’t pay for content, yet if you manage to get popular, you can make money off of sponsored posts. “Hey, say something nice about our company, here’s $x”. That’s not really social, but it’s how ‘influencers’ make money these days: sponsored posts. When you get paid to write posts in that way, you might be selling your soul unless you keep a good moral compass, but when bills need to get paid, that moral compass sometimes goes out the window. I won’t say everyone is like that, I will say it’s a danger and why I don’t care much about ‘influencers’.
In my mind, anyone who is an influencer is trying to sell me something, or has an ego so large that Zaphod Beeblebrox would be insanely jealous.
Regardless, to get popular, you have to contribute content. Who owns LinkedIn? Microsoft. Who is Microsoft partnered with? OpenAI. The dots are there. Maybe they’re not connected. Maybe they are.
Other websites are out there that are building on user content. The odds are good that they have more money for lawyers than you do, that their content licensing and user agreement work for them and not you, and if someone wants to buy that content for any reason… you’ll find out what users on Stack Overflow found out.
All relationships are built on trust. All networks are built on trust. The Internet is built on trust.
I volunteered some stuff to WorldChanging.com way back when with the understanding it would be Creative Commons licensed. I went back and forth with Alex and Jamais, as did a few other contributors, and because of that and some nastiness related to the Alert Retrieval Cache, I walked away from the site to find out from an editor that contacted me about their book that they wanted to use some of my work. Nope. I don’t trust futurists, and maybe you shouldn’t either.↩︎
I always seemed to be the software engineer that could make sense out of gobblygook code, rein it in, take it to water and convince it to drink.↩︎
The premise of the study seemed weird from the start: What would be the point of it? Why is it that someone thought to compare the carbon footprints of humans and AI for generating images and text? What burning question was trying to be answered?
Is the argument to be that there should be less humans? The way things are going on the planet, that almost seems plausible – people warring and killing people could say, “We’re reducing the carbon footprint of humanity!”, get some carbon credits for it and feel good about their contributions – except if protests around the world are any indicator, that may not sell well.
The answer is likely that since people have been pointing out that the carbon footprint of generative AI is high, they want to be able to have a rebuttal. But there are some questions.
To calculate the carbon footprint of a person writing, we consider the per capita emissions of individuals in different countries. For instance, the emission footprint of a US resident is approximately 15 metric tons CO2e per year22, which translates to roughly 1.7 kg CO2e per hour. Assuming that a person’s emissions while writing are consistent with their overall annual impact, we estimate that the carbon footprint for a US resident producing a page of text (250 words) is approximately 1400 g CO2e. In contrast, a resident of India has an annual impact of 1.9 metric tons22, equating to around 180 g CO2e per page. In this analysis, we use the US and India as examples of countries with the highest and lowest per capita impact among large countries (over 300 M population).
What they don’t take into account – to the detriment of we lowly human writers – is that the physical act of writing so many words an hour is not all of writing. In fact, all of writing – real writing – requires the lifetime of sensory inputs as well as thought up to that point. Words don’t just fall out of humans.
This point is important because it’s also true of generative AI. Generative AI is certainly trained on large datasets, but those datasets have come from… where? They therefore inherit the human writer carbon footprint, which would be higher since they have stolen used materials that humans created to feed the training model. Further, every human involved in that process, as well as the maintenance of the system, adds to the carbon footprint. Then there are the materials in the GPUs, the integration, etc.
So sure, maybe in generating a few thousand words – we presently call that ‘slop’ – it can do someone’s homework or help one write a monotonous study (they did use ChatGPT3), that carbon footprint might seem to be lower, but overall I’d say that it was actually higher than the average human overall.
Because we humans, in having our average carbon footprint, do other things that raise it: we drive to work, we use electricity to power devices pitched to us to increase our productivity, we cook meals, etc. All of that – all of that – is being added into the mix as if it has no value.
Before generative AI came around, nobody pointed at writers and said, “Those people just have this carbon footprint and they don’t do anything. We should create a generative AI that does it.”. In fact, nobody actually asked for any of that. Then, to have work written by writers sucked into a learning model to be used to generate text to create more slop – of questionable quality, of dubious value, being generated to spam the Internet with – and I apologize to real Spam – less nutritional value and taste.
AI art is much the same, I imagine, but I can’t really draw to save my life and have had the good fortune not to have to. I wrote something about using AI art in blogs that explains my usage, but I would never tell my visual art friends that AI has a lower carbon footprint.
The whole study seems funded by some company that wants a rebuttal to carbon footprints. It is, at best, very limited in how it views the carbon footprints of both we lowly humans and our esteemed ‘colleagues’, generative AI. At worst, it’s meant to prop up propaganda marketing for AI and the people who make the point that on top of the human carbon footprint, generative AI adds significantly more.
Unless, of course, this is a study to demonstrate that we need fewer people and we should do something about it – which some governments are doing right now, unfortunately.