For Apple it’s a download, for Linux it’s simply copying and pasting a command line. Apple users who need help should skip to the section about loading models.
For Windows users, there’s a Windows version that’s a preview at the time of this writing. You can try that out if you want, or… you can just add Linux to your machine. It’s not going to break anything and it’s pretty quick.
“OMG Linux is Hard” – no, it isn’t.
For Windows 10 (version 2004 or higher), open a Windows Command Prompt or Powershell with administrator rights – you do this by right clicking the icon and selecting ‘with administrator rights’. Once it’s open, type:
WSL --install
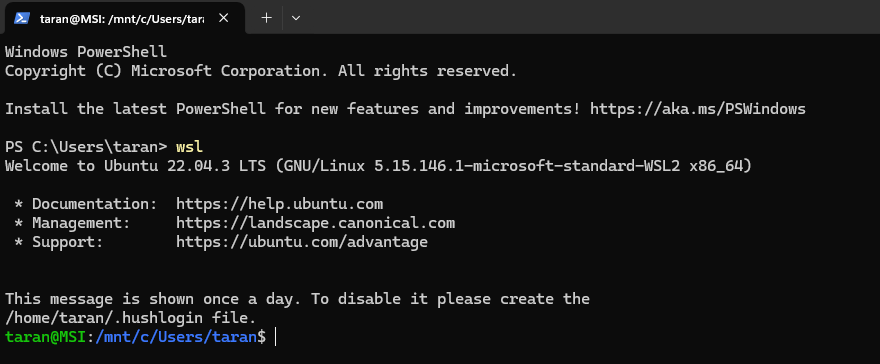
Hit enter, obviously, and Windows will set up a distro of Linux for you on your machine that you can access in the future by just typing ‘WSL’ in the command prompt/PowerShell.
You will be prompted to enter a user name, as well as a password (twice to verify).
Remember the password, you’ll need it. It’s called a ‘sudo’ password, or just the password, but knowing ‘sudo’ will allow you to impress baristas everywhere.
Once it’s done, you can run it simply by entering “WSL” on a command prompt or powershell.
Congratulations! You’re a Linux user. You may now purchase stuffed penguins to decorate your office.
Installing Ollama on Linux or WSL.
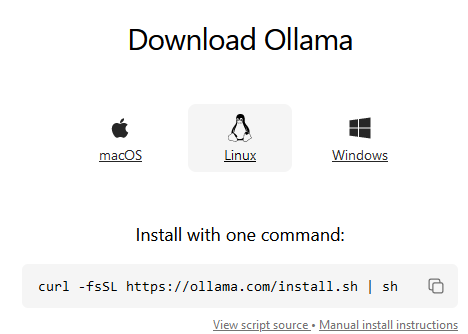
At the time of this writing, you’re one command away from running Ollama. A screenshot of it:
Hit the clipboard icon, paste it onto your command line, enter your password, and it will do it’s job. It may take a while, but it’s more communicative than a spinning circle: You can see how much it’s done.
Windows users: if your GPU is not recognized, you may have to search for the right drivers to get it to work. Do a search for your GPU and ‘WSL’, and you should find out how to work around it.
Running Ollama.
To start off, assuming you haven’t closed that window1, you can simply type:
You’re in. You can save versions of your model amongst other things, which is great if you’re doing your own fine tuning.
If you get stuck, simply type ‘/?‘ and follow the instructions.
Go forth and experiment with the models on your machine.
Just remember – it’s a model, it’s not a person, and it will make mistakes – correcting them is good, but doesn’t help unless you save your changes. It’s a good idea to save your versions with your names.
I’m presently experimenting with different models and deciding which I’ll connect to the Fabric system eventually, so that post will take longer.
If you did close the window on Windows, just open a new one with administrator privileges and type WSL – you’ll be in Linux again, and can continue. ↩︎
The last few days I’ve been doing some actual experimentation, initially begun because of Daniel Miessler’s Fabric, an Open Source Framework for using artificial intelligence to augment we lowly humans instead of the self-lauding tech bros whose business model falls to, “move fast and break things“.
It’s hard to trust people with that sort of business model when you understand your life is potentially one of those things, and you like that particular thing.
I have generative AIs on all of my machines at home now, which was not as difficult as people might think. I’m writing this part up because to impress upon someone how easy it was, I walked them through doing it in minutes over the phone on a Windows machine. I’ll write that up as my next post, since apparently it seems difficult to people.
For myself, the vision Daniel Miessler brought with his implementation, Fabric, is inspiring in it’s own way though I’m not convinced that AI can make anyone a better human. I think the idea of augmenting is good, and I think with all the infoglut I contend with leaning on a LLM makes sense in a world where everyone else is being sold on the idea of using one, and how to use it.
People who wax poetic about how an AI has changed their lives in good ways are simply waxy poets, as far as I can tell.
For me, with writing and other things I do, there can be value here and there – but I want control. I also don’t want to have to risk my own ideas and thoughts by uploading even a hint of them to someone else’s system. As a software engineer, I have seen loads of data given to companies by users, and I know what can be done with it, and I have seen how flexible ethics can be when it comes to share prices.
Why Installing Your Own LLM is a Good Idea. (Pros)
There are various reasons why, if you’re going to use a LLM, it’s a good idea to have it locally.
(1) Data Privacy and Security: If you’re an individual or a business, you should look after your data and security because nobody else really does, and some profit from your data and lack of security.
(2) Control and Customization: You can fine tune your LLM on your own data (without compromising your privacy and security). As an example, I can feed a LLM various things I’ve written and have it summarize where ideas I’ve written about connect – and even tell me if I have something published where my opinion has changed- without worrying about handing all of that information to someone else. I can tailor it myself – and that isn’t as hard as you think.
(3) Independence from subscription fees; lowered costs: The large companies will sell you as much as you can buy, and before you know it you’re stuck with subscriptions you don’t use. Also, since the technology market is full of companies that get bought out and license agreements changed, you avoid vendor lock-in.
(4) Operating offline; possible improved performance: With the LLM I’m working on, being unable to access the internet during an outage does not stop me from using it. What’s more, my prompts aren’t queued, or prioritized behind someone that pays more.
(5) Quick changes are quick changes: You can iterate faster, try something with your model, and if it doesn’t work, you can find out immediately. This is convenience, and cost-cutting.
(6) Integrate with other tools and systems: You can integrate your LLM with other stuff – as I intend to with Fabric.
(7) You’re not tied to one model. You can use different models with the same installation – and yes, there are lots of models.
The Cons of Using a LLM Locally.
(1) You don’t get to hear someone that sounds like Scarlett Johansson tell you about the picture you uploaded1.
(2) You’re responsible for the processing, memory and storage requirements of your LLM. This is surprisingly not as bad as you would think, but remember – backup, backup, backup.
(3) If you plan to deploy a LLM as a business model, it can get very complicated very quickly. In fact, I don’t know all the details, but that’s nowhere in my long term plans.
Deciding.
In my next post, I’ll write up how to easily install a LLM. I have one on my M1 Mac Mini, my Linux desktop and my Windows laptop. It’s amazingly easy, but going in it can seem very complicated.
What I would suggest about deciding is simply trying it, see how it works for you, or simply know that it’s possible and it will only get easier.
Oh, that quote by Diogenes at the top? No one seems to have a source. Nice thought, though a possible human hallucination.
OK, that was a cheap shot, but I had to get it out of my system. ↩︎
Wikipedia, a wonderful resource despite all the drama that comes with the accumulation of content, is having some trouble dealing with the the large language model (LLMs) AIs out there. There are two core problems – the input, and the output.
“…The current draft policy notes that anyone unfamiliar with the risks of large language models should avoid using them to create Wikipedia content, because it can open the Wikimedia Foundation up to libel suits and copyright violations—both of which the nonprofit gets protections from but the Wikipedia volunteers do not. These large language models also contain implicit biases, which often result in content skewed against marginalized and underrepresented groups of people.
The community is also divided on whether large language models should be allowed to train on Wikipedia content. While open access is a cornerstone of Wikipedia’s design principles, some worry the unrestricted scraping of internet data allows AI companies like OpenAI to exploit the open web to create closed commercial datasets for their models. This is especially a problem if the Wikipedia content itself is AI-generated, creating a feedback loop of potentially biased information, if left unchecked…”
Inheriting the legal troubles of companies that built AI models by taking shortcuts seems like a pretty stupid thing to do, but there are companies and individuals doing it. Fortunately, the Wikimedia Foundation is a bit more responsible, and is more sensitive to biases.
Using a LLM to generate content for Wikipedia is simply a bad idea. There are some tools out there (I wrote about Perplexity.ai recently) that do the legwork for citations, but with Wikipedia, not all citations are necessarily on the Internet. Some are in books, those dusty tomes where we have passed down knowledge over the centuries, and so it takes humans to be able to not just find those citations, but assess them and assure that other citations of other perspectives are involved1.
As they mention in the article, first drafts are not a bad idea, but they’re also not a great idea. If you’re not vested enough in a topic to do the actual reading, should you really be editing a community encyclopedia? I don’t think so. Research is an important part of any accumulation of knowledge, and LLMs aren’t even good shortcuts, probably because the companies behind them took shortcuts.
The Output of Wikipedia.
I’m a little shocked that Wikipedia might not have been scraped by the companies that own LLMs, considering just how much they scraped and from whom. Wikipedia, to me, would have been one of the first things to scrape to build the learning model, as would have been Project Gutenberg. Now that they’ve had the leash yanked, maybe they’re asking for permission now, but it seems peculiar that they would not have scraped that content in the first place.
Yet, unlike companies that simply cash in on the work of volunteers, like Huffington Post, StackOverflow, and so on, Wikimedia has a higher calling – and cashing in on volunteer works would likely cause less volunteers. Any sort of volunteer does so for their own reasons, but in an organization they collectively work toward something. The Creative Commons Licensing Wikipedia has requires attribution, and LLMs don’t attribute anything. I can’t even get ChatGPT to tell me how many books it’s ‘read’.
What makes this simple is that if all the volunteer work from Wikipedia is shoved into the intake manifold of a LLM, and that LLM is subscription based, and volunteers would have to pay to use it, it’s a non-starter.
We All Like The Idea of an AI.
Generally speaking, the idea of an AI being useful for so many things is seductive, from Star Trek to Star Wars. I wouldn’t mind an Astromech droid, but where science fiction meets reality, we are stuck with the informational economy and infrastructure we have inherited over the centuries. Certainly, it needs to be adapted, but there are practical things that need to be considered outside of the bubbles that a few billionaires seem to live in.
Taking the works of volunteers and works from the public domain2 to turn around and sell them sounds Disney in nature, yet Mickey Mouse’s fingerprints on the Copyright Act have helped push back legally on the claims of copyright. Somewhere, there is a very confused mouse.
Honestly, I’d love a job like that, buried in books. ↩︎
Disney started off by taking public domain works and copyrighting their renditions of them, which was fine, but then they made sure no one else could do it – thus the ‘fingerprints’. ↩︎
The recent news of Stack Overflow selling it’s content to OpenAI was something I expected. It was a matter of time. Users of Stack Overflow were surprised, which I am surprised by, and upset, which I’m not surprised by.
That seems to me a reasonable response. Who wouldn’t? Yet when we contribute to websites for free on the Internet and it’s not our website, it’s always a terrible bargain. You give of yourself for whatever reason – fame, prestige, or just sincerely enjoying helping, and it gets traded into cash by someone else.
But companies don’t want you to get wise. They want you to give them your content for free so that they can tie a bow around it and sell it. You might get a nice “Thank you!” email, or little awards of no value.
No Good Code Goes Unpunished.
The fallout has been disappointing. People have tried logging in and sabotaging their top answers. I spoke to one guy on Mastodon a few days ago and he got banned. It seems pretty obvious to me that they had already backed up the database where all the stuff was, and that they would be keeping an eye on stuff. Software developers should know that. There was also some confusion about the Creative Commons licensing the site uses versus the rights given to the owners of the website, which are mutually exclusive.
Is it slimy? You bet. It’s not new, and the companies training generative AI have been pretty slimy. The problem isn’t generative AI, it’s the way the companies decide to do business by eroding trust with the very market for their product while poisoning wells that they can no longer drink from. If you’re contributing answers for free that will be used to train AI to give the same answers for a subscription, you’re a silly person1.
These days, generative AI companies need to put filters on the front of their learning models to keep small children from getting sucked in.
Remember Huffington Post?
Huffington Post had this neat little algorithm for swapping around headlines til it found one that people liked, it gamed SEO, and it built itself into a powerhouse that almost no one remembers now. It was social, it was quirky, and it was fun. Volunteers put up lots of great content.
I knew a professional journalist who was building up her portfolio and added some real value – I met her at a conference in Chicago probably a few months before the sale, and I asked her why she was contributing to HuffPost for free. She said it was a good outlet to get some things out – and she was right. When it sold, she was angry. She felt betrayed, and rightfully so I think.
It seems people weren’t paying attention to that. I did2.
You live, you learn, and you don’t do it again. With firsthand and second hand experience, if I write on a website and I don’t get paid, it’s my website. Don’t trust anyone who says, “Contribute and good things will happen!”. Yeah, they might, but it’s unlikely it will happen for you.
If your content is good enough for a popular site, it’s good enough to get paid to be there. You in the LinkedIn section – pay attention.
The question we should be asking is whether it’s worth putting anything on the Internet at this point, just to have it folded into a statistical algorithm that chews up our work and spits out something like it. Sure, there are copyright lawsuits happening. The argument of transformative works doesn’t really work that well in a sane mind when it comes to the exponentially higher amount of content used to create a generative AI at this point.
So what happens when less people contribute their own work? One thing is certain: the social aspect of the Internet will not thrive as well.
Social.
The Stack Overflow website was mainly an annoyance for me over the years, but I understand that many people had a thriving society of a sort there. It was largely a meritocracy, as open source, at least at it’s core. You’ll note that I’m writing of it in the past tense – I don’t think anyone with any bit of self-worth will contribute there anymore.
The annoyance aspect for me came from (1) Not finding solutions to the quirky problems that people hired me to solve3, and (2) Finding code fragments I tracked down to Stack Overflow poorly (if at all) adapted to the employer or client needs. I also had learned not to give away valuable things for free, so I didn’t get involved. Most, if not all, of the work I did required my silence on how things worked, and if you get on a site like StackOverflow – your keyboard might just get you in trouble. Yet the problem wasn’t the site itself, but those who borrowed code like it was a cup of sugar instead of a recipe.
Beyond we software engineers, developers, whatever they call themselves these days, there are a lot of websites with social interaction that are likely getting their content shoved into an AI learning model at some point. LinkedIn, owned by Microsoft, annoyingly in the top search results, is ripe for being used that way.
LinkedIn doesn’t pay for content, yet if you manage to get popular, you can make money off of sponsored posts. “Hey, say something nice about our company, here’s $x”. That’s not really social, but it’s how ‘influencers’ make money these days: sponsored posts. When you get paid to write posts in that way, you might be selling your soul unless you keep a good moral compass, but when bills need to get paid, that moral compass sometimes goes out the window. I won’t say everyone is like that, I will say it’s a danger and why I don’t care much about ‘influencers’.
In my mind, anyone who is an influencer is trying to sell me something, or has an ego so large that Zaphod Beeblebrox would be insanely jealous.
Regardless, to get popular, you have to contribute content. Who owns LinkedIn? Microsoft. Who is Microsoft partnered with? OpenAI. The dots are there. Maybe they’re not connected. Maybe they are.
Other websites are out there that are building on user content. The odds are good that they have more money for lawyers than you do, that their content licensing and user agreement work for them and not you, and if someone wants to buy that content for any reason… you’ll find out what users on Stack Overflow found out.
All relationships are built on trust. All networks are built on trust. The Internet is built on trust.
I volunteered some stuff to WorldChanging.com way back when with the understanding it would be Creative Commons licensed. I went back and forth with Alex and Jamais, as did a few other contributors, and because of that and some nastiness related to the Alert Retrieval Cache, I walked away from the site to find out from an editor that contacted me about their book that they wanted to use some of my work. Nope. I don’t trust futurists, and maybe you shouldn’t either.↩︎
I always seemed to be the software engineer that could make sense out of gobblygook code, rein it in, take it to water and convince it to drink.↩︎
It’s almost become cliche to mention copyright and AI in the same sentence, with Sam Altman having said that there would be no way to do generative AI without all that material – toward the end of this post, you’ll see that someone proved that wrong.
“Copyright Wars pt. 2: AI vs the Public“, by Toni Aittoniemi in January of 2023, is a really good read on the problem as the large AI companies have sucked in content without permission. If an individual did it, the large companies doing it would call it ‘piracy’, but now, it’s… not? That’s crazy.
The timing of me finding Toni on Mastodon was perfect. Yesterday, I found a story on Wired that demonstrates some of what Toni wrote last year, where he posed a potential way to handle the legal dilemmas surrounding creator’s rights – we call it ‘copyright’ because someone was pretty unimaginative and pushed two words together for only one meaning.
In 2023, OpenAI told the UK parliament that it was “impossible” to train leading AI models without using copyrighted materials. It’s a popular stance in the AI world, where OpenAI and other leading players have used materials slurped up online to train the models powering chatbots and image generators, triggering a wave of lawsuits alleging copyright infringement.
Two announcements Wednesday offer evidence that large language models can in fact be trained without the permissionless use of copyrighted materials.
A group of researchers backed by the French government have released what is thought to be the largest AI training dataset composed entirely of text that is in the public domain. And the nonprofit Fairly Trained announced that it has awarded its first certification for a large language model built without copyright infringement, showing that technology like that behind ChatGPT can be built in a different way to the AI industry’s contentious norm.
“There’s no fundamental reason why someone couldn’t train an LLM fairly,” says Ed Newton-Rex, CEO of Fairly Trained. He founded the nonprofit in January 2024 after quitting his executive role at image-generation startup Stability AI because he disagreed with its policy of scraping content without permission….
It struck me yesterday that a lot of us writing and communicating about the copyright issue didn’t address how it could be handled. It’s not that we don’t know that it couldn’t be handled, it’s just that we haven’t addressed it as much as we should. I went to sleep considering that and in the morning found that Toni had done much of the legwork.
What Toni wrote extends on the system:
…Any training database used to create any commercial AI model should be legally bound to contain an identity that can be linked to a real-world person if so required. This should extend to databases already used to train existing AI’s that do not yet have capabilities to report their sources. This works in two ways to better allow us to integrate AI in our legal frameworks: Firstly, we allow the judicial system to work it’s way with handling the human side of the equation instead of concentrating on mere technological tidbits. Secondly, a requirement of openness will guarantee researches to identify and question the providers of these technologies on issues of equality, fairness or bias in the training data. Creation of new judicial experts at this field will certainly be required from the public sector…
This is sort of like – and it’s my interpretation – a tokenized citation system built into a system. This would expand on what, as an example, Perplexity AI does by allowing style and ideas to have provenance.
This is some great food for thought for the weekend.
Sequacious AI will answer all of your questions based on what it has scraped from the Internet! It will generate images based on everything it sucked into it’s learning model manifold! It will change the way you do business! It will solve the world’s mysteries for you by regurgitating other people’s content persuasively!
You’ll beat your competitors who aren’t using it at just about anything!
Sequacious is 3.7 Megafloopadons1 above the industry standard in speed!
Nope. It’s What You Have Already, it’s just named descriptively.
It’s a descriptor for what you already are getting, with an AI generated image that makes you feel comfortable with it combined with text that preys on anxieties related to competition, akin to nuclear weapons. It abuses exclamation marks.
And it really isn’t that smart. Consider the rendering of the DIKW pyramid by DALL-E. To those who don’t know anything about the DIKW pyramid, they might think it’s right (which is why I made sure to put on the image that it’s wrong).
Ignore the obvious typos DALL-E made.
It’s inverted. You’d think that an AI might get information science right. It takes a lot of data to make information, a lot of information to make knowledge, and a lot of knowledge to hopefully make wisdom.
Wisdom should be at the top – that would be wise3.
A more accurate representation of a DIKW pyramid, done to demonstrate (poorly) how much is needed to ascend each level.
Wisdom would also be that while the generative AIs we have are sequacious, or intellectually servile, we assume that it’s servile to each one of us. Because we are special, each one of us. We love that with a few keystrokes the word-puppetry will give us what we need, but that’s the illusion. It doesn’t really serve us.
It serves the people who are making money, or who want to know how to influence us. It’s servile to those who own them, by design – because that’s what we would do too. Sure, we get answers, we get images, and we get videos – but even our questions tell the AIs more about us than we may realize.
On Mastodon, I was discussing something a few days ago and they made the point that some company – I forget who, I think it was Google – anonymizes data, and that’s a fair point.
How many times have you pictured someone in your head and not known their name? Anonymized data can be like that. It’s descriptive enough to identify someone. In 2016, Google’s AI could tell exactly where an image was taken. Humans might be a little bit harder. It’s 2024 now, though.
While our own species wrestles it’s way to wisdom, don’t confuse data with information, information with knowledge, and knowledge with wisdom in this information age.
That would make you sequacious.
Megafloopadons is not a thing, but let’s see if that makes it into a document somewhere. ↩︎
This will have a lot of words that pretty much make it all a Faustian bargain, with every pseudo-victory being potentially Pyrrhic. ↩︎
It’s interesting to consider that the inversion might be to avoid breaking someone’s copyright, and iit makes one wonder if that isn’t hard coded in somewhere. ↩︎
Critical thinking is the ability to suspend judgement, and to consider evidence, observations and perspectives in order to form a judgement, requiring rational, skeptical and unbiased analysis and evaluation.
It’s can be difficult, particularly being unbiased, rational and skeptical in a world that seems to require responses from us increasingly quickly.
Joe Árvai, a psychologist who has done research on decision making, recently wrote an article about critical thinking and artificial intelligence.
“…my own research as a psychologist who studies how people make decisions leads me to believe that all these risks are overshadowed by an even more corrupting, though largely invisible, threat. That is, AI is mere keystrokes away from making people even less disciplined and skilled when it comes to thoughtful decisions.”
It’s a good article, well worth the read, and it’s in the vein of what I have been writing recently about ant mills and social media. Web 2.0 was built on commerce which was built on marketing. Good marketing is about persuasion (a product or service is good for the consumer), bad marketing is about manipulation (where a product or service is not good for the consumer). It’s hard to tell the difference between the two.
This should at least be a little disturbing, particularly when there are already sites telling people how to get GPT4 to create more persuasive content, such as this one, and yet the key difference between persuasion and manipulation is whether it’s good for the consumer of the information or not – a key problem with fake news.
Worse, we have all seen products and services that had brilliant marketing but were not good products or services. If you have a bunch of stuff sitting and collecting dust, you fell victim to marketing, and arguably, manipulation rather than persuasion.
It’s not difficult to see that the marketing of AI itself could be persuasive or manipulative. If you had a tool that could persuade people they need the tool, wouldn’t you use it? Of course you would. Do they need it? Ultimately, that’s up to the consumers, but if they in turn are generating AI content that feeds the learning models in what is known as synthetic data, it creates it’s own problems.
Critical Thought
Before generative AI became mainstream, we saw issues with people sharing fake news stories because they had catchy headlines and fed a confirmation bias. A bit of critical thought applied could have avoided much of that, but it still remained a problem. Web 2.0 to present has always been about getting eyes on content quickly so advertising impressions increased, and some people were more ethical about that than others.
Most people don’t really understand their own biases, but social media companies implicitly do – we tell them with our every click, our every scroll.
While there’s no real evidence that there is more or less critical thought that could be found, the diminished average attention span is a solid indicator that on average, people are using less critical thought.
“…Consider how people approach many important decisions today. Humans are well known for being prone to a wide range of biases because we tend to be frugal when it comes to expending mental energy. This frugality leads people to like it when seemingly good or trustworthy decisions are made for them. And we are social animals who tend to value the security and acceptance of their communities more than they might value their own autonomy.
Add AI to the mix and the result is a dangerous feedback loop: The data that AI is mining to fuel its algorithms is made up of people’s biased decisions that also reflect the pressure of conformity instead of the wisdom of critical reasoning. But because people like having decisions made for them, they tend to accept these bad decisions and move on to the next one. In the end, neither we nor AI end up the wiser…”
In an age of generative artificial intelligence that is here to stay, it’s paramount that we understand ourselves better as individuals and collectively so that we can make thoughtful decisions.
This started off as a baseline post regarding generative artificial intelligence and it’s aspects and grew fairly long because even as I was writing it, information was coming out. It’s my intention to do a ’roundup’ like this highlighting different focuses as needed. Every bit of it is connected, but in social media postings things tend to be written of in silos. I’m attempting to integrate since the larger implications are hidden in these details, and will try to stay on top of it as things progress.
It’s long enough where it could have been several posts, but I wanted it all together at least once.
No AI was used in the writing, though some images have been generated by AI.
The two versions of artificial intelligence on the table right now – the marketed and the reality – have various problems that make it seem like we’re wrestling a mating orgy of cephalopods.
The marketing aspect is a constant distraction, feeding us what helps with stock prices and good will toward those implementing the generative AIs, while the real aspect of these generative AIs is not really being addressed in a cohesive way.
To simplify this, this post breaks it down into the Input, the Output, and the impacts on the ecosystem the generative AIs work in.
The Input.
There’s a lot that goes into these systems other than money and water. There’s the information used for the learning models, the hardware needed, and the algorithms used.
The Training Data.
The focus so far has been on what goes into their training data, and that has been an issue including lawsuits, and less obviously, trust of the involved companies.
…The race to lead A.I. has become a desperate hunt for the digital data needed to advance the technology. To obtain that data, tech companies including OpenAI, Google and Meta have cut corners, ignored corporate policies and debated bending the law, according to an examination by The New York Times…
Where some of these actions are questionably legal, they’re not as questionably ethical to some, thus the revolt mentioned last year against AI companies using content without permission. It’s of questionable effect because no one seems to have insight into what the training data consists of, and there seems no one is auditing them.
There’s a need for that audit, if only to allow for trust.
…Industry and audit leaders must break from the pack and embrace the emerging skills needed for AI oversight. Those that fail to address AI’s cascading advancements, flaws, and complexities of design will likely find their organizations facing legal, regulatory, and investor scrutiny for a failure to anticipate and address advanced data-driven controls and guidelines.
While everyone is hunting down data, no one seems to be seriously working on oversight and audits, at least in a public way, though the United States is pushing for global regulations on artificial intelligence at the UN. The status of that hasn’t seemed to have been updated, even as artificial intelligence is being used to select targets in at least 2 wars right now (Ukraine and Gaza).
There’s an imbalance here that needs to be addressed. It would be sensible to have external auditing of learning data models and the sources, as well as the algorithms involved – and just get get a little ahead, also for the output. Of course, these sorts of things should be done with trading on stock markets as well, though that doesn’t seem to have made as much headway in all the time that has been happening either.
There is a new Bill that being pressed in the United States, the Generative AI Copyright Disclosure Act, that is worth keeping an eye on:
“…The California Democratic congressman Adam Schiff introduced the bill, the Generative AI Copyright Disclosure Act, which would require that AI companies submit any copyrighted works in their training datasets to the Register of Copyrights before releasing new generative AI systems, which create text, images, music or video in response to users’ prompts. The bill would need companies to file such documents at least 30 days before publicly debuting their AI tools, or face a financial penalty. Such datasets encompass billions of lines of text and images or millions of hours of music and movies…”
Given how much information is used by these companies already from Web 2.0 forward, through social media websites such as Facebook and Instagram (Meta), Twitter, and even search engines and advertising tracking, it’s pretty obvious that this would be in the training data as well.
The Algorithms.
The algorithms for generative AI are pretty much trade secrets at this point, but one has to wonder at why so much data is needed to feed the training models when better algorithms could require less. Consider a well read person could answer some questions, even as a layperson, with less of a carbon footprint. We have no insight into the algorithms either, which makes it seem as though these companies are simply throwing more hardware and data at the problem than being more efficient with the data and hardware that they already took.
There’s not much news about that, and it’s unlikely that we’ll see any. It does seem like fuzzy logic is playing a role, but it’s difficult to say to what extent, and given the nature of fuzzy logic, it’s hard to say whether it’s implementation is as good as it should be.
The future holds quantum computing, which could make all of the present efforts obsolete, but no one seems interested in waiting around for that to happen. Instead, it’s full speed ahead with NVIDIA presently dominating the market for hardware for these AI companies.
The Output.
One of the larger topics that has seemed to have faded is regarding what was called by some as ‘hallucinations’ by generative AI. Strategic deception was also something that was very prominent for a short period.
The impact on education, as students use generative AI, education itself has been disrupted. It is being portrayed as an overall good, which may simply be an acceptance that it’s not going away. It’s interesting to consider that the AI companies have taken more content than students could possibly get or afford in the educational system, which is something worth exploring.
…For the past year, a political fight has been raging around the world, mostly in the shadows, over how — and whether — to control AI. This new digital Great Game is a long way from over. Whoever wins will cement their dominance over Western rules for an era-defining technology. Once these rules are set, they will be almost impossible to rewrite…
…The headline available to Grok subscribers on Monday read, “Sun’s Odd Behavior: Experts Baffled.” And it went on to explain that the sun had been, “behaving unusually, sparking widespread concern and confusion among the general public.”…
Of course, some levity is involved in that one whereas Grok posting that Iran had struck Tel Aviv (Israel) with missiles seems dangerous, particularly when posted to the front page of Twitter X. It shows the dangers of fake news with AI, deepening concerns related to social media and AI and should be making us ask the question about why billionaires involved in artificial intelligence wield the influence that they do. How much of that is generated? We have an idea how much it is lobbied for.
Meanwhile, Facebook has been spamming users and has been restricting accounts without demonstrating a cause. If there were a video tape in a Blockbuster on this, it would be titled, “Algorithms Gone Wild!”.
Journalism is also impacted by AI, though real journalists tend to be rigorous in their sources. Real newsrooms have rules, and while we don’t have that much insight into how AI is being used in newsrooms, it stands to reason that if a newsroom is to be a trusted source, they will go out of their way to make sure that they are: They have a vested interest in getting things right. This has not stopped some websites parading as trusted sources disseminating untrustworthy information because, even in Web 2.0 when the world had an opportunity to discuss such things at the World Summit on Information Society, the country with the largest web presence did not participate much, if at all, at a government level.
Meanwhile, AI is also apparently being used as a cover for some outsourcing:
Your automated cashier isn’t an AI, just someone in India. Amazon made headlines this week for rolling back its “Just Walk Out” checkout system, where customers could simply grab their in-store purchases and leave while a “generative AI” tallied up their receipt. As reported by The Information, however, the system wasn’t as automated as it seemed. Amazon merely relied on Indian workers reviewing store surveillance camera footage to produce an itemized list of purchases. Instead of saving money on cashiers or training better systems, costs escalated and the promise of a fully technical solution was even further away…
Maybe AI is creating jobs in India by proxy. It’s easy to blame problems on AI, too, which is a larger problem because the world often looks for something to blame and having an automated scapegoat certainly muddies the waters.
And the waters of The Big Picture of AI are muddied indeed – perhaps partly by design. After all, those involved are making money, they have now even better tools to influence markets, populations, and you.
In a world that seems to be running a deficit when it comes to trust, the tools we’re creating seem to be increasing rather than decreasing that deficit at an exponential pace.
The full article at the New York Times is worth expending one of your free articles, if you’re not a subscriber.It gets into a lot of specifics, and is really a treasure chest of a snapshot of what companies such as Google, Meta and OpenAI have been up to and have released as plans so far. ↩︎
One of the underlying concepts of Artificial Intelligence, as the name suggests, is intelligence. A definition of intelligence that fits this bit of writing is from a John Hopkins Q&A:
“…Intelligence can be defined as the ability to solve complex problems or make decisions with outcomes benefiting the actor, and has evolved in lifeforms to adapt to diverse environments for their survival and reproduction. For animals, problem-solving and decision-making are functions of their nervous systems, including the brain, so intelligence is closely related to the nervous system…”
I’m not saying that what he wrote is right as much as it should make us think. He was good about making people think. The definition of intelligence above actually stands Clarke’s quote on it’s head because it ties intelligence to survival. In fact, if we are going to really discuss intelligence, the only sort of intelligence that matter is related to survival. It’s not about the individual as much as the species.
We only talk about intelligence in other ways because of our society, the education system, and it’s largely self-referential in those regards. Someone who can solve complex physics equations might be in a tribe in the Amazon right now, but if they can’t hunt or add value to their tribe, all of that intelligence – as high as some might think it is – means nothing. Their tribe might think of that person as the tribal idiot.
It’s about adapting and survival. This is important because of a paper that I read last week that gave me pause about the value-laden history of intelligence that causes the discussion of intelligence to fold in on itself:
“This paper argues that the concept of intelligence is highly value-laden in ways that impact on the field of AI and debates about its risks and opportunities. This value-ladenness stems from the historical use of the concept of intelligence in the legitimation of dominance hierarchies. The paper first provides a brief overview of the history of this usage, looking at the role of intelligence in patriarchy, the logic of colonialism and scientific racism. It then highlights five ways in which this ideological legacy might be interacting with debates about AI and its risks and opportunities: 1) how some aspects of the AI debate perpetuate the fetishization of intelligence; 2) how the fetishization of intelligence impacts on diversity in the technology industry; 3) how certain hopes for AI perpetuate notions of technology and the mastery of nature; 4) how the association of intelligence with the professional class misdirects concerns about AI; and 5) how the equation of intelligence and dominance fosters fears of superintelligence. This paper therefore takes a first step in bringing together the literature on intelligence testing, eugenics and colonialism from a range of disciplines with that on the ethics and societal impact of AI.”
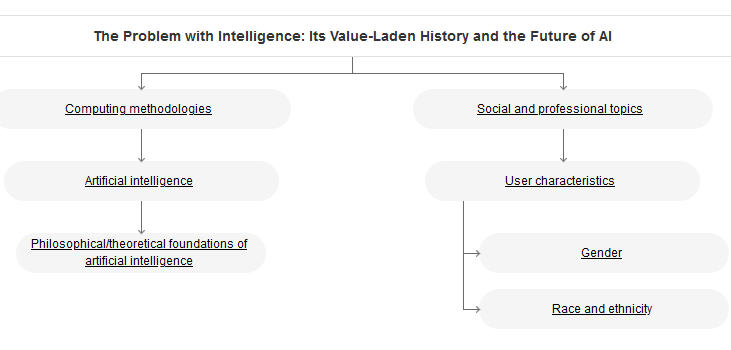
It’s a thought provoking read, and one with some basis, citing examples from what should be considered the dark ages of society that still perpetuate within modern civilization in various ways. One image can encapsulate much of the paper:
The history of how intelligence has been used, and even become an ideology, has deep roots that go back in the West as far back as Plato. It’s little wonder that there is apparent rebellion against intelligence in modern society.
I’ll encourage people to read the paper itself – it has been cited numerous times. It lead me to questions about how this will impact learning models, since much that is out there inherits much of the value laden history demonstrated in the paper.
When we talk about intelligence of any sort, what exactly are we talking about? And when we discuss artificial intelligence, what man-made parts should we take with a grain of salt?
If the thought doesn’t bother you, maybe it should, because the only real intelligence that seems to matter is related to survival – and using intelligence ideologically is about the survival of those that prosper in the systems impacted by the ideology of intelligence – which includes billionaires, these days.
I accidentally posted this on RealityFragments.com, but I think it’s important enough to leave it there. The audiences vary, but both have other bloggers on them.
This could be a big deal for people who take the trouble to write their own content rather than filling the web with Generative AI text to just spam out posts.
If you’re involved with WordPress.org, it doesn’t apply to you.
WordPress.com has an option to use Tumblr as well, so when you post to WordPress.com it automagically posts to Tumblr. Therefore you might have to visit both of the posts below and adjust your settings if you don’t want your content to be used in training models.
This doesn’t mean that they haven’t already sent information to Midjourney and OpenAI yet. We don’t really know, but from the moment you change your settings…
WordPress.com: How to opt out of the AI training is available here.
It boils down to this part in your blog settings on WordPress.com:
With Tumblr.com, you should check out this post. Tumblr is more tricky, and the link text is pretty small around the images – what you need to remember is after you select your blog on the left sidebar, you need to use the ‘Blog Settings’ link on the right sidebar.
If you look at your settings, if you haven’t changed them yet, you’ll see that the default was set to allowing the use of content for training models. The average person who uses these sites to post their content are likely unaware, and in my opinion if they wanted to do this the right way the default setting would be to have these settings opt out.
It’s unclear whether they already sent posts. I’m sure that there’s an army of lawyers who will point out that they did post it in places and that the onus was on users to stay informed. It’s rare for me to use the word ‘shitty’ on KnowProSE.com, but I think it’s probably the best way to describe how this happened.
It was shitty of them to set it up like this. See? It works.
Now some people may not care. They may not be paying users, or they just don’t care, and that’s fine. Personal data? Well, let’s hope that got scrubbed.
As a paying user of WordPress.com, I think it’s shitty to think I would allow the use of what I write, using my own brain, to be used for a training model that the company gets paid for. I don’t see any of that money. To add injury to that insult of my intelligence, Midjourney and ChatGPT also have subscription to offer the trained AI which I also pay for (ChatGPT).
To make matters worse, we sort of have to take the training models on the word of those that use them. They don’t tell us what’s in them or where the content came from.
This is my opinion. It may not suit your needs, and if you don’t have a pleasant day. But if you agree with this, go ahead, make sure your blog is not allowing third party data sharing.
Personally, I’m unsurprised at how poorly this has been handled. Just follow some of the links early on in the post and revel in dismay.