
As I wrote in the last post, there are some good reasons to install your own LLM on your computer. It’s all really simple using Ollama, which allows you to run various models of LLM on your computer.
A GPU is nice, but not required.
Apple and Linux Users can simply go right over to Ollama and just follow the instructions.
For Apple it’s a download, for Linux it’s simply copying and pasting a command line. Apple users who need help should skip to the section about loading models.
For Windows users, there’s a Windows version that’s a preview at the time of this writing. You can try that out if you want, or… you can just add Linux to your machine. It’s not going to break anything and it’s pretty quick.
“OMG Linux is Hard” – no, it isn’t.
For Windows 10 (version 2004 or higher), open a Windows Command Prompt or Powershell with administrator rights – you do this by right clicking the icon and selecting ‘with administrator rights’. Once it’s open, type:
WSL --installHit enter, obviously, and Windows will set up a distro of Linux for you on your machine that you can access in the future by just typing ‘WSL’ in the command prompt/PowerShell.
You will be prompted to enter a user name, as well as a password (twice to verify).
Remember the password, you’ll need it. It’s called a ‘sudo’ password, or just the password, but knowing ‘sudo’ will allow you to impress baristas everywhere.
Once it’s done, you can run it simply by entering “WSL” on a command prompt or powershell.
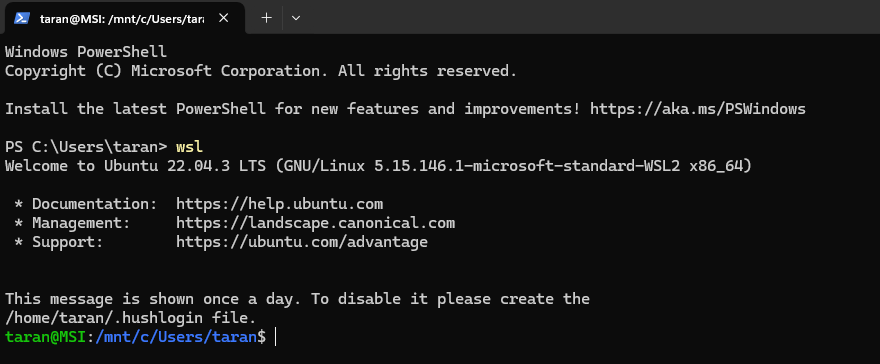
Congratulations! You’re a Linux user. You may now purchase stuffed penguins to decorate your office.
Installing Ollama on Linux or WSL.
At the time of this writing, you’re one command away from running Ollama. A screenshot of it:
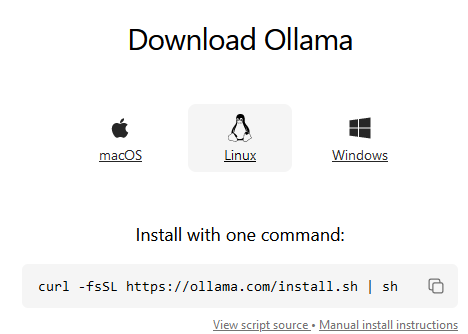
Hit the clipboard icon, paste it onto your command line, enter your password, and it will do it’s job. It may take a while, but it’s more communicative than a spinning circle: You can see how much it’s done.
Windows users: if your GPU is not recognized, you may have to search for the right drivers to get it to work. Do a search for your GPU and ‘WSL’, and you should find out how to work around it.
Running Ollama.
To start off, assuming you haven’t closed that window1, you can simply type:
ollama run <insert model name here>
Where you can pick a model name from the library. Llama3 is at the top of the list, so as an example:
ollama run llama3
You’re in. You can save versions of your model amongst other things, which is great if you’re doing your own fine tuning.
If you get stuck, simply type ‘/?‘ and follow the instructions.
Go forth and experiment with the models on your machine.
Just remember – it’s a model, it’s not a person, and it will make mistakes – correcting them is good, but doesn’t help unless you save your changes. It’s a good idea to save your versions with your names.
I’m presently experimenting with different models and deciding which I’ll connect to the Fabric system eventually, so that post will take longer.
- If you did close the window on Windows, just open a new one with administrator privileges and type WSL – you’ll be in Linux again, and can continue. ↩︎
